TL;DR
gom stands for GPU Output Monitor. It's a pip package that provides a CLI for monitoring GPU usage. Think of it as nvidia-smi, but faster and more minimalist. And it has a bonus feature: in environments where Docker containers are using GPUs, it will break down usage by container! (Don't worry, it also works in environments without Docker and even inside Docker containers.)
I owe my colleague Vin credit for inspiring this project. He used GPT-4 to create an initial prototype in Bash, but I had to rewrite from scratch due to bugs and performance issues.
Instructions
- Run
pip3 install gom - Depending on your CUDA version, install the correct version of
pynvml - Run
gom show(to show usage once) orgom watch(to monitor usage, updated roughly every second)
Comparing gom and nvidia-smi
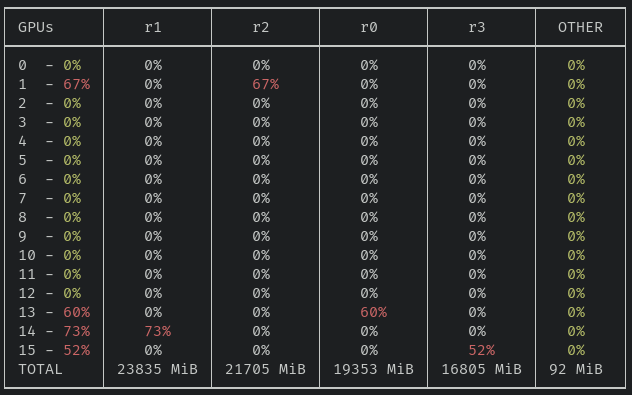
I think the results speak for themselves :). This first screenshot is the result of running gom watch. You can see that four different Docker containers, r0, r1, r2, and r3, are each using a GPU quite heavily. There's also slight usage of all GPUs that's not coming from any container.
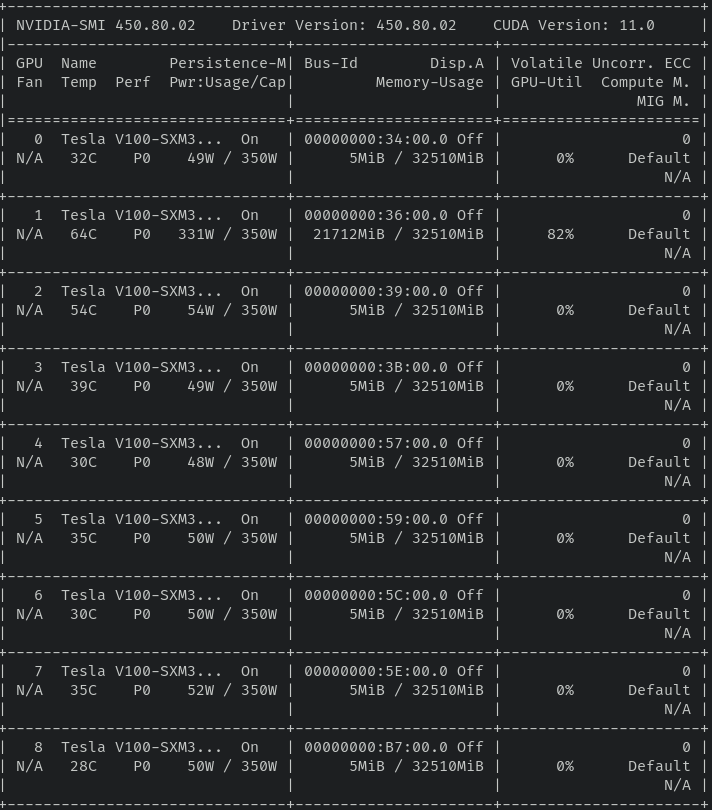
This second screenshot is the result of running nvidia-smi. It's complex and unnecessarily verbose. In more space than gom, it only manages to show information for 8 GPUs!
Conclusion
I created gom because I wanted to monitor GPU usage across different Docker containers. I use it frequently when doing ML tasks because it's fast and the output fits on a small terminal. Hopefully it's helpful for you. If you have suggestions, feel free to open an issue at the GitHub repo.